
머신러닝(Machine Learning) 모델을 구축하는 과정에서 가장 중요한 단계 중 하나는 모델의 성능을 평가하는 것입니다. 모델이 얼마나 잘 작동하는지 이해하고, 개선이 필요한 부분을 식별하며, 여러 모델 중에서 최적의 선택을 하기 위해 **성능지표(Performance Metrics)**를 사용합니다. 이 글에서는 머신러닝에서 주로 사용되는 성능지표들을 살펴보고, 각 지표의 특징과 활용 방법을 상세히 설명합니다.
목차
- 머신러닝 성능지표란 무엇인가?
- 데이터 유형에 따른 성능지표 선택
- 주요 머신러닝 성능지표
- 3.1 분류(Classification) 성능지표
- 정확도(Accuracy)
- 정밀도(Precision)
- 재현율(Recall)
- F1 점수(F1 Score)
- ROC-AUC
- 3.2 회귀(Regression) 성능지표
- 평균 제곱 오차(MSE)
- 평균 절대 오차(MAE)
- 결정 계수(R²)
- MAPE
- 3.3 클러스터링(Clustering) 성능지표
- 실루엣 계수(Silhouette Score)
- 엘보우 방법(Elbow Method)
- 3.1 분류(Classification) 성능지표
- 성능지표를 선택할 때 고려해야 할 점
- 성능지표를 통한 모델 최적화 전략
- 결론
1. 머신러닝 성능지표란 무엇인가?
머신러닝 성능지표란 학습된 모델이 주어진 데이터에 대해 얼마나 잘 예측했는지를 수치화한 평가 기준입니다. 모델이 만들어내는 결과가 정확한지, 효율적인지, 실사용에 적합한지를 측정하는 데 사용됩니다. 성능지표는 데이터의 유형(분류, 회귀, 클러스터링 등)과 모델의 목적에 따라 달라질 수 있습니다.
2. 데이터 유형에 따른 성능지표 선택
모델의 종류와 데이터 특성에 따라 성능지표를 다르게 선택해야 합니다.
- 분류(Classification): 예측값이 범주형 데이터인 경우(예: 스팸 메일 여부), 정확도나 정밀도 같은 지표를 주로 사용합니다.
- 회귀(Regression): 예측값이 연속형 데이터인 경우(예: 집값 예측), 평균 제곱 오차(MSE)와 같은 지표가 적합합니다.
- 클러스터링(Clustering): 데이터가 어떤 군집에 속하는지를 분석하는 경우(예: 고객 세분화), 군집의 품질을 측정하는 실루엣 계수(Silhouette Score)를 사용할 수 있습니다.
3. 주요 머신러닝 성능지표
3.1 분류(Classification) 성능지표
(1) 정확도(Accuracy)
- 정의: 전체 데이터 중에서 모델이 올바르게 예측한 비율입니다.
- 공식:
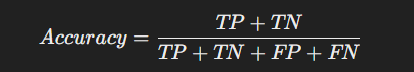
(TP: True Positive, TN: True Negative, FP: False Positive, FN: False Negative)
- 장점: 간단하고 직관적임.
- 단점: 데이터가 불균형(예: 90%가 한 클래스)할 경우 정확도가 높더라도 모델의 성능이 낮을 수 있음.
(2) 정밀도(Precision)
- 정의: 양성으로 예측한 값 중 실제로 양성인 데이터의 비율입니다.
- 공식:
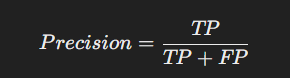
- 장점: False Positive(거짓 양성)를 줄이는 데 유리함.
- 활용 예시: 스팸 메일 분류(정밀도가 높아야 정상 메일을 스팸으로 분류하는 실수를 줄일 수 있음).
(3) 재현율(Recall)
- 정의: 실제 양성 데이터 중에서 모델이 양성으로 올바르게 예측한 비율입니다
- 공식:
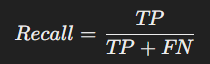
- 장점: False Negative(거짓 음성)를 줄이는 데 유리함.
- 활용 예시: 암 진단(재현율이 높아야 암을 놓치는 경우를 최소화할 수 있음).
(4) F1 점수(F1 Score)
- 정의: 정밀도와 재현율의 조화 평균으로, 두 지표 간 균형을 평가합니다.
- 공식:

- 장점: 데이터 불균형 상황에서도 적합한 평가 지표.
- 활용 예시: 정밀도와 재현율이 모두 중요한 경우(예: 의료 데이터 분석).
(5) ROC-AUC (Receiver Operating Characteristic – Area Under Curve)
- 정의: ROC 곡선 아래 면적을 계산한 값으로, 모델의 분류 성능을 종합적으로 평가합니다.
- 특징: AUC 값이 1에 가까울수록 성능이 우수합니다.
- 활용 예시: 모델의 전반적인 예측력을 평가할 때 사용.
3.2 회귀(Regression) 성능지표
(1) 평균 제곱 오차(MSE, Mean Squared Error)
- 정의: 예측값과 실제값의 차이를 제곱하여 평균낸 값입니다.
- 공식:
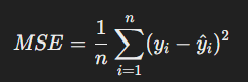
- 특징: 오류값을 제곱하여 큰 오류에 더 높은 페널티를 부여함.
(2) 평균 절대 오차(MAE, Mean Absolute Error)
- 정의: 예측값과 실제값의 차이의 절댓값을 평균낸 값입니다.
- 공식:
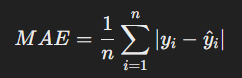
- 특징: MSE보다 이상치에 덜 민감함.
(3) 결정 계수(R²)
- 정의: 모델이 데이터를 얼마나 잘 설명하는지 나타냄.
- 공식:

- 특징: R² 값이 1에 가까울수록 모델이 잘 맞습니다.
3.3 클러스터링(Clustering) 성능지표
(1) 실루엣 계수(Silhouette Score)
- 정의: 클러스터 간의 거리와 클러스터 내의 밀집도를 평가합니다.
- 특징: -1에서 1 사이의 값을 가지며, 1에 가까울수록 우수함.
(2) 엘보우 방법(Elbow Method)
- 정의: 클러스터 수에 따른 SSE(오차 제곱합)의 감소를 시각화하여 최적의 클러스터 수를 찾는 방법입니다.
4. 성능지표를 선택할 때 고려해야 할 점
- 문제 유형: 분류인지 회귀인지에 따라 지표를 다르게 선택.
- 데이터 특성: 클래스 불균형, 이상치 여부 등.
- 비즈니스 목표: False Positive와 False Negative의 중요성을 구분.
5. 성능지표를 통한 모델 최적화 전략
- 데이터 증강: 데이터 불균형 문제를 해결하기 위해 오버샘플링(SMOTE)이나 언더샘플링 기법을 사용.
- 모델 튜닝: 하이퍼파라미터 최적화(Grid Search, Random Search 등).
- 지표 간 균형 고려: 정밀도-재현율 트레이드오프를 이해하고, F1 점수를 최적화.
6. 맺음말
머신러닝 성능지표는 모델의 성공 여부를 판단하고, 개선 방안을 찾는 데 필수적입니다. 데이터 유형과 문제의 특성을 고려하여 적합한 지표를 선택하고, 이를 바탕으로 모델을 지속적으로 개선해 나가는 것이 중요합니다. 성능지표를 제대로 활용한다면, 더 나은 모델을 구축하고 비즈니스 목표를 효과적으로 달성할 수 있습니다.
2930 Blog에서 더 알아보기
구독을 신청하면 최신 게시물을 이메일로 받아볼 수 있습니다.