
1. 머신러닝이란?
**머신러닝(Machine Learning)**은 컴퓨터가 명시적인 프로그래밍 없이 데이터를 분석하고 학습하여 패턴을 인식하고 예측을 수행할 수 있도록 하는 인공지능(AI)의 한 분야입니다.
이 과정에서 머신러닝 알고리즘은 데이터를 처리하고, 학습하며, 최적의 모델을 생성하는 역할을 합니다.
2. 머신러닝 알고리즘의 분류
머신러닝 알고리즘은 주로 학습 방식에 따라 다음과 같이 분류됩니다.
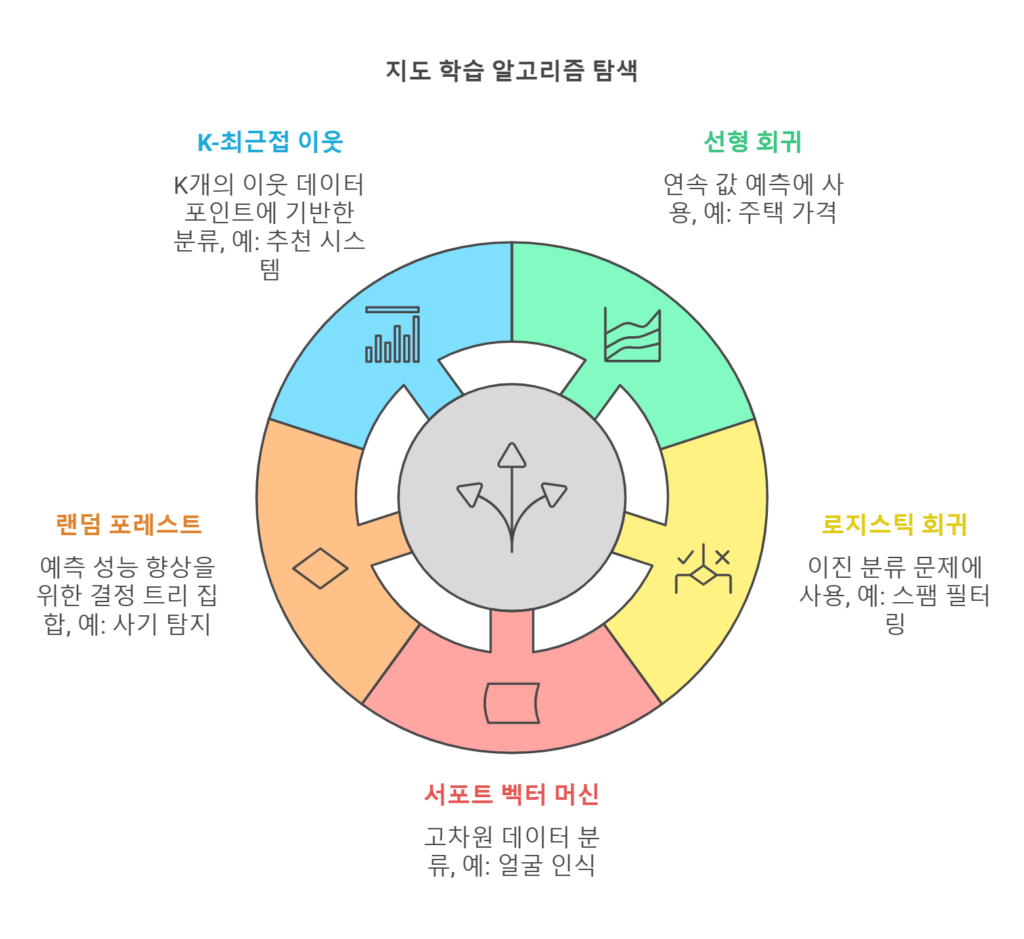
2.1 지도 학습(Supervised Learning)
- 정의: 입력 데이터와 그에 해당하는 **정답(레이블)**이 주어진 상태에서 학습.
- 목적: 주어진 데이터를 통해 입력과 출력 간의 관계를 학습하고, 새로운 데이터에 대해 예측 수행.
주요 알고리즘:
- 선형 회귀(Linear Regression):
- 연속적인 숫자 값을 예측하는 데 사용.
- 예: 주택 가격 예측.
- 로지스틱 회귀(Logistic Regression):
- 이진 또는 다중 클래스 분류 문제에 사용.
- 예: 이메일 스팸 필터링.
- 서포트 벡터 머신(SVM):
- 고차원 공간에서 데이터를 분류하기 위한 초평면 생성.
- 예: 얼굴 인식.
- 랜덤 포레스트(Random Forest):
- 다수의 결정 트리를 결합하여 예측 성능 향상.
- 예: 사기 거래 탐지.
- K-최근접 이웃(K-Nearest Neighbors):
- 데이터 포인트의 근처에 있는 K개의 이웃을 기반으로 분류.
- 예: 추천 시스템.
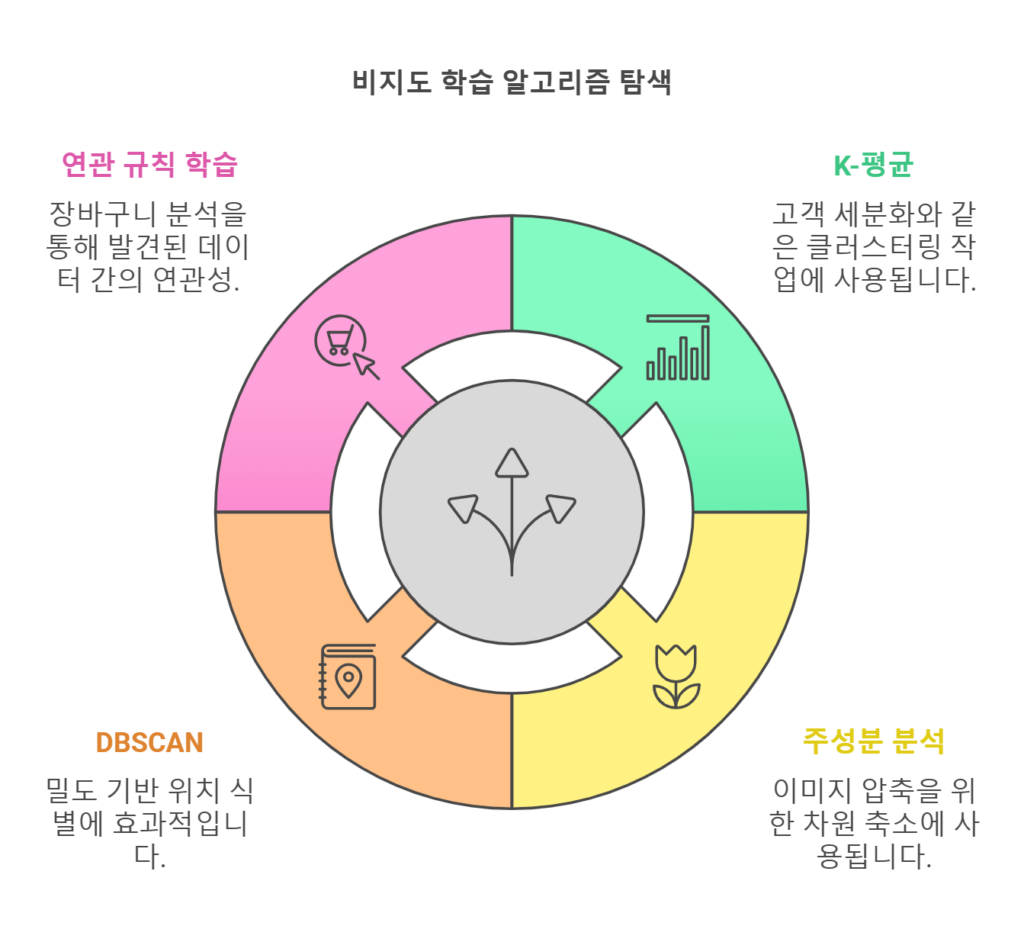
2.2 비지도 학습(Unsupervised Learning)
- 정의: 데이터에 레이블이 없는 상태에서 패턴을 찾는 방식.
- 목적: 데이터의 구조와 숨겨진 관계를 이해하거나 데이터를 군집화.
주요 알고리즘:
- K-평균(K-Means):
- 데이터를 K개의 클러스터로 나눔.
- 예: 고객 세분화.
- 주성분 분석(PCA):
- 데이터의 차원을 축소하여 주요 특징 추출.
- 예: 이미지 압축.
- DBSCAN:
- 밀도를 기반으로 데이터 클러스터를 식별.
- 예: 지도에서 위치 기반 군집화.
- 연관 규칙 학습(Association Rule Learning):
- 데이터 간의 연관성을 발견.
- 예: 장바구니 분석.
2.3 강화 학습(Reinforcement Learning)
- 정의: 행동과 보상의 피드백 루프를 통해 학습.
- 목적: 에이전트가 환경과 상호작용하며 최적의 행동을 선택.
주요 알고리즘:
- Q-러닝(Q-Learning):
- 상태와 행동의 조합에 대한 보상을 학습.
- 예: 로봇의 경로 최적화.
- 딥 Q-네트워크(DQN):
- 강화 학습에 딥러닝을 결합하여 복잡한 문제 해결.
- 예: 게임 AI(알파고).
2.4 준지도 학습(Semi-Supervised Learning)
- 정의: 소량의 레이블 데이터와 대량의 비레이블 데이터를 함께 사용하여 학습.
- 목적: 적은 양의 레이블 데이터로도 높은 성능을 달성.
활용 예:
- 의료 데이터 분석(많은 비레이블 데이터 활용).
- 자연어 처리(NLP)에서의 언어 모델 학습.
3. 머신러닝 알고리즘의 주요 활용 사례
3.1 이미지 처리
- 활용: 객체 탐지, 이미지 분류, 얼굴 인식.
- 알고리즘: CNN(Convolutional Neural Network), Random Forest.
3.2 자연어 처리(NLP)
- 활용: 번역, 감정 분석, 챗봇.
- 알고리즘: RNN(Recurrent Neural Network), 트랜스포머(Transformer).
3.3 예측 분석
- 활용: 주식 가격 예측, 날씨 예보.
- 알고리즘: 선형 회귀, LSTM(Long Short-Term Memory).
3.4 추천 시스템
- 활용: 전자 상거래, 콘텐츠 스트리밍.
- 알고리즘: 협업 필터링(Collaborative Filtering), KNN.
4. 머신러닝 알고리즘의 선택 기준
- 문제 유형:
- 예측(회귀, 분류) 또는 데이터 구조 분석(클러스터링, 차원 축소)인지에 따라 선택.
- 데이터 크기와 품질:
- 대규모 데이터: 딥러닝 알고리즘 적합.
- 소규모 데이터: 결정 트리, SVM 등 사용.
- 모델 복잡성:
- 간단한 문제에는 선형 회귀나 KNN과 같은 단순 알고리즘.
- 복잡한 문제에는 앙상블 학습이나 딥러닝 모델.
- 해석 가능성:
- 해석이 중요한 문제에는 선형 회귀나 결정 트리 사용.
- 예측 정확도가 중요하면 앙상블 또는 딥러닝 선택.
5. 머신러닝 알고리즘의 도전 과제
- 과적합(Overfitting):
- 모델이 학습 데이터에 과도하게 맞춰져 새로운 데이터에서 성능 저하.
- 해결 방법: 정규화, 교차 검증, 드롭아웃.
- 데이터 불균형:
- 한 클래스가 과도하게 많아 학습 결과가 왜곡.
- 해결 방법: SMOTE(샘플 증대), 가중치 조정.
- 학습 속도:
- 대규모 데이터와 복잡한 모델로 인해 학습 시간이 길어짐.
- 해결 방법: GPU/TPU 활용, 샘플링 기법.
- 특성 선택:
- 불필요한 특성이 모델 성능에 부정적인 영향을 미칠 수 있음.
- 해결 방법: 특성 중요도 분석, 차원 축소 기법.
6. 머신러닝의 미래와 전망
- AutoML:
- 모델 선택과 하이퍼파라미터 튜닝을 자동화하여 비전문가도 머신러닝 활용 가능.
- AI와 머신러닝의 융합:
- 딥러닝과 강화 학습을 통한 자율적인 학습 시스템.
- 실시간 분석:
- 실시간 데이터를 처리하여 예측과 의사결정을 지원.
- 도메인 특화 모델:
- 의료, 금융, 제조 등 특정 산업에 맞춘 알고리즘 개발.
7. 맺음말
머신러닝 알고리즘은 데이터로부터 학습하여 다양한 문제를 해결할 수 있는 강력한 도구입니다. 지도 학습, 비지도 학습, 강화 학습 등 다양한 학습 방식이 존재하며, 문제 유형과 데이터 특성에 따라 적합한 알고리즘을 선택하는 것이 중요합니다.
기술 발전과 함께 머신러닝은 더 많은 산업과 일상에 깊숙이 침투하며, 기업과 개인 모두에게 새로운 가능성과 경쟁력을 제공하고 있습니다. 🚀
2930 Blog에서 더 알아보기
구독을 신청하면 최신 게시물을 이메일로 받아볼 수 있습니다.