
1. 랜덤 포레스트란?
**랜덤 포레스트(Random Forest)**는 앙상블 학습(Ensemble Learning) 기법의 하나로, 여러 개의 결정 트리(Decision Trees)를 결합하여 예측 성능을 향상시키는 알고리즘입니다.
이 모델은 분류(Classification)와 회귀(Regression) 문제에서 뛰어난 성능을 발휘하며, 데이터의 노이즈와 과적합 문제에 강한 특징을 가지고 있습니다.
2. 랜덤 포레스트의 핵심 아이디어
2.1 결정 트리의 한계
- 과적합(Overfitting): 단일 결정 트리는 학습 데이터에 너무 맞춰져 새로운 데이터에 대해 성능이 낮아질 수 있음.
- 불안정성: 데이터가 조금만 변경되어도 트리의 구조가 크게 달라질 수 있음.
2.2 앙상블 학습으로 해결
랜덤 포레스트는 다음과 같은 방식으로 단일 트리의 한계를 극복합니다.
- 다수결 또는 평균화: 여러 결정 트리의 예측 결과를 종합하여 최종 결과를 도출.
- 랜덤성 추가: 각 트리가 학습할 데이터를 랜덤하게 선택하고, 분할 기준에 랜덤성을 부여하여 트리 간의 상관성을 줄임.
3. 랜덤 포레스트의 작동 원리
3.1 학습 과정
- 부트스트랩 샘플링(Bootstrap Sampling):
- 원본 데이터에서 중복을 허용하여 무작위로 샘플을 선택해 여러 데이터셋 생성.
- 각 샘플은 전체 데이터의 일부를 포함.
- 결정 트리 학습:
- 각 부트스트랩 샘플을 사용하여 독립적인 결정 트리 생성.
- 분할 기준(feature 선택)에 랜덤성을 추가:
- 각 노드에서 분할할 때, 전체 특성 중 일부만 랜덤하게 선택하여 최적의 특성을 결정.
- 예측:
- 분류(Classification): 각 트리의 예측 결과 중 다수결로 최종 클래스 결정.
- 회귀(Regression): 각 트리의 예측 값을 평균 내어 최종 예측 값 계산.
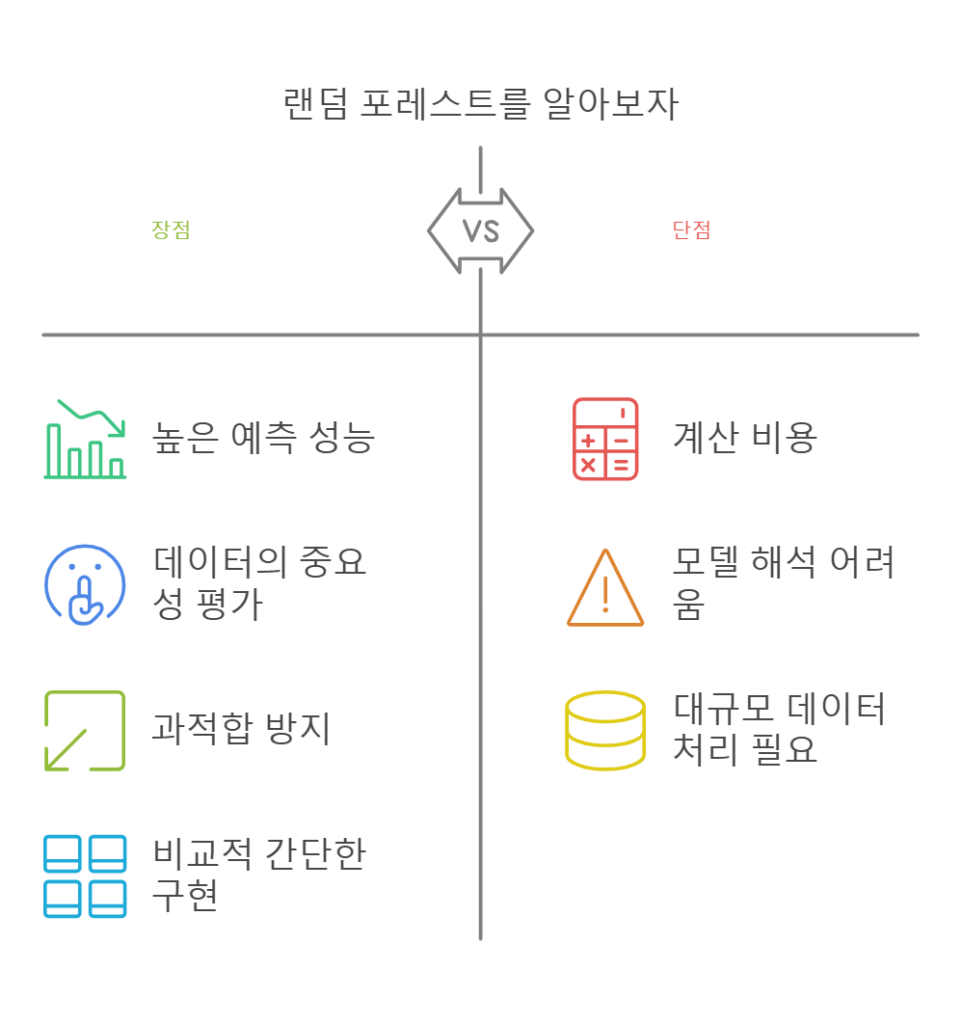
4. 랜덤 포레스트의 장점과 단점
4.1 장점
- 높은 예측 성능:
- 여러 트리의 결과를 결합하여 과적합을 방지하고 일반화 성능 향상.
- 노이즈에 강함:
- 일부 데이터의 노이즈가 모델 전체에 미치는 영향을 최소화.
- 다양한 데이터 처리:
- 분류, 회귀, 다차원 데이터에 모두 사용 가능.
- 특성 중요도 제공:
- 각 특성이 결과에 미치는 영향을 정량적으로 제공.
4.2 단점
- 계산 비용:
- 많은 트리를 학습시키기 때문에 학습 시간과 메모리 사용량이 큼.
- 해석 어려움:
- 단일 트리와 달리 랜덤 포레스트는 결과 해석이 어려움.
- 매우 고차원의 데이터에서 비효율적:
- 특성이 너무 많으면 각 트리가 분할 기준을 찾는 데 시간이 오래 걸림.
5. 랜덤 포레스트의 주요 하이퍼파라미터
5.1 주요 설정 값
- n_estimators (트리 개수):
- 생성할 트리의 개수.
- 많을수록 성능은 안정적이나 계산 비용 증가.
- max_features (최대 특성 수):
- 각 노드에서 분할 시 고려할 특성의 개수.
- 기본값은
sqrt(특성 수)(분류) 또는전체 특성 수(회귀).
- max_depth (최대 트리 깊이):
- 트리의 깊이를 제한하여 과적합 방지.
- min_samples_split, min_samples_leaf (분할 기준):
- 분할 또는 리프 노드에 필요한 최소 샘플 수를 제한하여 과적합 방지.
- bootstrap:
- 부트스트랩 샘플링 여부를 결정.
6. 랜덤 포레스트 실습 예제 (Python)
6.1 데이터 준비
<python>
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
6.2 랜덤 포레스트 모델 생성
<python>
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 모델 생성
model = RandomForestClassifier(n_estimators=100, random_state=42)
# 모델 훈련
model.fit(X_train, y_train)
# 예측
y_pred = model.predict(X_test)
# 성능 평가
accuracy = accuracy_score(y_test, y_pred)
print(f"정확도: {accuracy:.2f}")
6.3 특성 중요도 확인
<python>
import matplotlib.pyplot as plt
# 특성 중요도 시각화
feature_importances = model.feature_importances_
plt.bar(range(len(feature_importances)), feature_importances)
plt.title("Feature Importances")
plt.show()
7. 랜덤 포레스트의 응용 분야
7.1 분류 문제
- 의료: 질병 진단.
- 금융: 사기 거래 탐지.
- 소셜 미디어: 스팸 필터링.
7.2 회귀 문제
- 부동산: 주택 가격 예측.
- 기후: 온도 및 강수량 예측.
7.3 특성 중요도 분석
- 머신러닝 모델에서 주요 특성을 식별하여 비즈니스 인사이트 제공.
8. 랜덤 포레스트와 다른 알고리즘 비교
| 알고리즘 | 특징 |
|---|---|
| 결정 트리 | 단순하고 직관적이나, 과적합 위험이 높음. |
| 배깅(Bagging) | 데이터 샘플링과 평균화 기법으로 단일 트리의 한계를 극복. |
| 랜덤 포레스트 | 배깅에 추가적인 랜덤성을 부여하여 상관성을 줄이고 성능을 높임. |
| 부스팅(Boosting) | 약한 학습기를 연속적으로 학습시켜 오차를 줄임. 더 높은 성능을 내지만 학습 시간이 오래 걸림. |
9. 맺음말
랜덤 포레스트는 강력하고 유연한 머신러닝 알고리즘으로, 다양한 데이터 유형과 문제에 적용 가능합니다. 과적합 방지, 높은 예측 정확도, 노이즈에 강한 특성 덕분에 분류와 회귀 문제 모두에서 널리 사용됩니다.
그러나 계산 비용이 크고 해석이 어려울 수 있으므로, 적절한 하이퍼파라미터 튜닝과 데이터 크기에 따른 최적화를 통해 효율적으로 활용해야 합니다. 랜덤 포레스트는 복잡한 문제를 간단하고 효과적으로 해결할 수 있는 도구로, 머신러닝 실무에서 없어서는 안 될 중요한 알고리즘입니다. 🚀